Quando pensiamo all’intelligenza artificiale (AI) pensiamo a qualcosa di freddo, logico, senza pregiudizio. Molte intelligenze artificiali, però, mostrano invece pregiudizi e bias che riflettono quelli umani. Proviamo a capire quindi come sia possibile che un’intelligenza artificiale risulti bigotta.
L’intelligenza artificiale bigotta
Per capire come sia possibile che un’intelligenza artificiale sia bigotta bisogna innanzitutto capire cosa si intende quando si parla di AI. In realtà questo termine indica un’intera disciplina dedicata a capire se, attraverso sistemi informatici, sia possibile replicare o almeno simulare il pensiero complesso dell’essere umano.
Gli strumenti e le tecnologie, sia hardware che software, sono tantissimi e diversi tra di loro. C’è però un insieme di metodi, nati alla fine del ventesimo secolo ma diventati popolare nell’ultimo decennio grazie all’effettiva possibilità di metterli in pratica, racchiusi nel termine machine learning (o apprendimento automatico; ML in breve). Questi algoritmi di apprendimento, uniti al concetto di rete neurale come struttura da addestrare e che contiene al suo interno l’effettiva intelligenza artificiale, sono alla base di molte AI moderne.
Machine learning
Quando si sviluppa un algortimo “a mano” in modo da ottenere da un certo ingresso (es. le condizioni atmosferiche attuali) una certa uscita (es. le previsioni per domani), bisogna capire intimamente i meccanismi dell’algoritmo e le elaborazioni necessarie. Un processo che, in molti casi, può risultare, difficilissimo, se non impossibile, e che risulta ancora più difficile da generalizzare per ogni possibile variazione dell’input. Questo è particolarmente vero quando si vuole ricreare funzioni cognitive, visto che sappiamo ancora molto poco di come effettivamente il nostro cervello elabori determinate informazioni.
Il ML ribalta questa situazione. Ignorando i meccanismi interni dell’algoritmo, richiede solo una serie di coppie ingresso-uscita, degli esempi (in gergo si dice un dataset di addestramento). Partendo dagli ingressi le cui uscite desiderate sono note, il processo di ML è in grado di aggiustare le variabili interne dell’algoritmo. Il risultato è un sorta di AI in grado, nel contesto dell’ingresso e dell’uscita usati per l’addestramento, resistituire l’uscita giusta anche ad ingressi non usati nell’addestramento.
Proviamo a vedere un esempio. Se vogliamo un algortimo in grado di riconoscere la presenza di un cane in un’immagine, possiamo metterci lì e scervellarci su cosa effettivamente in una griglia di pixel è un possibile indicatore della presenza di un cane. Si tratta di un compito estremamente difficile, soprattutto nell’ottica di creare un algortimo generalizzato capace di funzionare con immagini anche molto diverse tra loro. Di contro è molto più semplice raccogliere moltissime immagini, con e senza cane, adeguatamente etichettate, e darle in pasto ad un algorimo di ML.
Il problema dei dati
Se da il ML sembra quasi magico nel creare un algoritmo di intelligenza artificiale, presenta diversi problemi. Quello che ci interessa per la nostra domanda iniziale è uno in particolare: la qualità dell’algoritmo è fortemente dipendente dalla qualità del dataset di addestramento.
Oltre a problemi pratici, come ottenere un dataset etichettato abbastanza espanso e diversificato, il problema concettuale è che qualunque bias presente nel dataset si riflette nell’algoritmo risultante. Il processo di ML infatti generalizzerà gli esempi, ma se questi esempi contengono un pregiudizio di qualche tipo, anche questo sarà generalizzato.
AI (troppo) umane
In qualche modo il problema non è neanche dell’intelligenza artificiale, ma umano. Il dataset di ImageNet, che contiene 14 milioni di immagini etichettate ed è utilizzato in un sacco per l’addestramento di AI “visive”, sovrappresenta persone e scenari dagli Stati Uniti rispetto ad altre parti del mondo, come Cina e India. Questo porta a risultati pregiudiziali, dove ad esempio un’immagine con persona vestita in un’abito da sposa occidentale è correttamente etichettata con “sposa”, “abito”, “donna” o “matrimonio”, ma il una persona con abito da sposa indiano ricade sotto “performance” o “costume”.
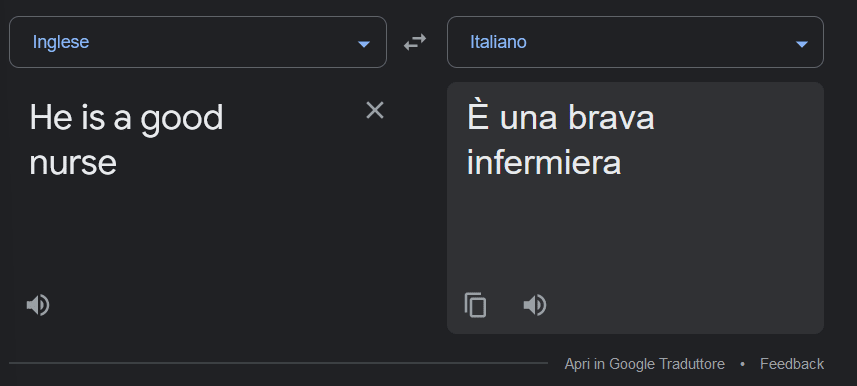
Un altro esempio riguarda la traduzione. Nelle traduzioni tra varie lingue, Google Translate tende ad assumere o addirittura a cambiare il genere dei soggetti coinvolti secondo quella che è l’aspettativa più comune e pregiudiziale.
Gli esempi sopra possono sembrare banali, ma questo tipo di sovra o sottorappresentazione può avere conseguenze anche molto gravi. Delle intelligenze artificiali usate in medicina per identificare tumori della pelle, e addestrate per lo più con immagini ottenute da Google con un programma automatizzato. Di queste, meno del 5% apparteneva a persone con la pelle scura. L’algortimo poi non è stato neanche testato su questa fascia di popolazione.
Un problema complesso
Il problema, come visto, è diffuso e complesso. Le AI hanno bisogno di dataset molto grandi per essere addestrate, perchè più il dataset è grande e variegato, più l’AI performerà meglio. I dataset già disponibili sono però spesso molto centrati su prospettive maschili e occidentali, se non proprio americane, sia dal punto di vista etnico che culturale che linguistico.
Comporre questi dataset, che devono essere etichettati a mano da studenti o da lavoratori sottopagati in contesti come Amazon Mechanical Turk, richiede un sacco di tempo e risorse e non sempre si garantisce una qualità maggiore e un’assenza di bias. Infine, non aiuta la mancanza di sensibilità (o di incentivi ad essere sensibili) che molte aziende e ambienti accademici hanno per il problema.
La soluzione deve per forza coinvolgere una consapevolezza maggior del problema e uno sforzo trasversale nel cercare di costruire dataset espansi, diversificati anche geograficamente, etnicamente e dal punto di vista del genere, mettendoli poi a disposizione di tutti. Alcuni ricercatori stanno già lavorando in questa direzione, ma la strada è ancora lunga.

- Use scikit-learn to track an example ML project end to end
- Gron, Aurlien (Autore)

- Mirjalili, Vahid (Autore)
Rimani aggiornato seguendoci su Google News!
Da non perdere questa settimana su Techprincess
🚪 La pericolosa backdoor di Linux, disastro sventato da un solo ricercatore
🎶Streaming Farms: il lato oscuro della musica, tra ascolti falsi e stream pompati
✈️Abbiamo provato DJI Avata 2: sempre più divertente!
✒️ La nostra imperdibile newsletter Caffellattech! Iscriviti qui
🎧 Ma lo sai che anche Fjona ha la sua newsletter?! Iscriviti a SuggeriPODCAST!
📺 Trovi Fjona anche su RAI Play con Touch - Impronta digitale!
💌 Risolviamo i tuoi problemi di cuore con B1NARY
🎧 Ascolta il nostro imperdibile podcast Le vie del Tech
💸E trovi un po' di offerte interessanti su Telegram!